DETR (vs Faster RCNN)
#transformer
paper,解读 ECCV 2020
解读
proposal base & anchor base & non anchor base
总结
ancor free, end-to-end, 避免了rule base的NMS
对RNN进行优化,实现并行,一口气预测一个集合
提出了新的detection metric——set prediction
framework
CNN Backbone + Transformer Encoder&Decoder + FFN预测层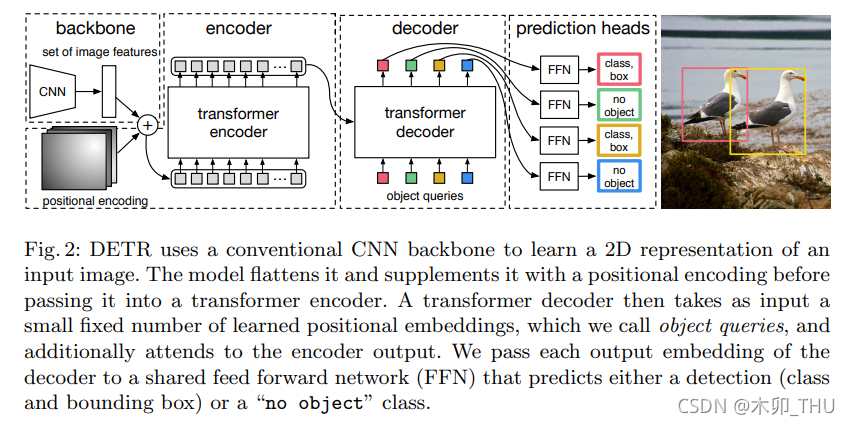
CNN Backbone (C=2048, HW 变为1/32)
还没有 swin transformer 这样的可以针对不同分辨率图像输入的 Transformer Backbone。目标检测的图一般比较大,那么直接上 Transformer 计算上吃不消,所以先用 CNN 进行特征提取并缩减尺寸,再使用 Transformer 是常规操作(或者说无奈之举)
Transformer Encoder
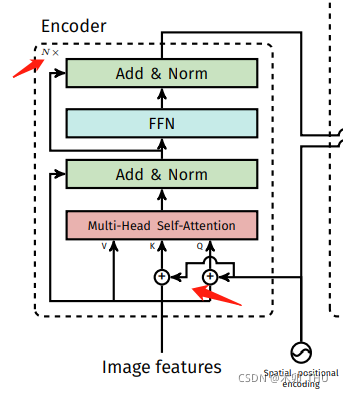
C=2048太大了,过1x1卷积核降维然后再输入 Transformer Encoder 会更好。
此时自注意力机制在特征图上进行全局分析,因为最后一个特征图对于大物体比较友好,那么在上面进行 Self-Attention 会便于网络更好的提取不同位置不同大物体之间的相互关系的联系,比如有桌子的地方可能有杯子,有草坪的地方有树,有一个鸟的地方可能还有一个鸟等等。所以 DETR 在大目标上效果比 Faster RCNN 好就比较容易理解到了。
然后位置编码是被每一个 Multi-Head Self-Attention 前都加入了的,这个就比较狠了。为了体现图像在 x 和 y 维度上的信息,作者的代码里分别计算了两个维度的 Positional Encoding,然后 cat 到一起。整个 Transformer Encoder 和之前的没什么不同。
Transformer Decoder
Transformer Decoder 也有几个地方需要着重强调。首先就是如何考虑同时进行一个集合预测?之前讲分类的时候都是给一个 class token,因为只进行一类预测。那么现在同时进行不知道多少类怎么办呢?因为目标预测框和输入 token 是一一对应的,所以最简单的做法就是给超多的查询 token,超过图像中会出现的目标的个数(在过去也是先生成 2000 个框再说)。所以在 DETR 中,作者选择了固定的 N = 100 个 token 作为输入,只能最多同时检测 100 个物体。据闻,这种操作可能跟 COCO 评测的时候取 top 100 的框有关。输入 100 个 decoder query slots (Object Query),并行解码N个object,对应的 Transformer decoder 也就会输出 100 个经过注意力和映射之后的 token,然后将它们同时喂给一个 FFN 就能得到 100 个框的位置和类别分数(因为是多分类,所以类别个数是 K + 1,1 指的是背景类别)。
固定预测个数更为简单,定长的输出有利于显存对齐,但是 N = 100 会不会冗杂呢?作者的实验表明,当图像内目标个数在 50 左右的时候,网络就已经区域饱和了,之后就会出现目标丢失。当图像内目标在一百个左右时,其实网络只能检测出来三四十个,这比图像中只有 50 个实例被检测到的情况还要少。作者认为出现这样反常的原因还是因为检测结果与训练分布相差甚远,是训练集中没有那么多多目标图片所造成的。
.png)
为了提升 AP,作者也坦然说到对应推理时出现的一些预测为背景的,用第二高分的类别覆盖这些槽的预测,使用相应的置信度。但是具体是怎么选的,比如背景概率在0.7以下使用还是怎么,就从论文中不可知了…
与 ViT 他们不同的另外一点是,DETR 的 Decoder 也加了 Positional Encoding。这个思想其实也很自然。当作图像分类是,其实 class token 就一个,对应整个图片,那么自然无需 positional encoding,自己把整个图都占全了。但是在做目标检测时,可能会希望不同的 Object Query 是不是对应图像中不同的位置会好一些。那么按照这个思想,Object Query 自然就是 positional encodings,也就是我就是要查询这里的物体,你预测出来的就是对应的如果有物体的话就是它的类别和位置。
怎么加,在哪里加 positional encodings? Transformer Decoder 做得比 Encoder 还要狠,不仅 encoder 用的那个 position encodings,也要给每层的 key 加上;Decoder 每一层的 query 还是加了 positional encodings (Object Query) 的。
-1.png)
还有一点值得注意的是:Decoder 每一层的输出结果也经过参数共享的最后的那个 FFN 进行预测并计算loss,实现 深监督。
-2.png)