VIT
#transformer
李沐: https://www.bilibili.com/video/BV15P4y137jb/?spm_id_from=333.788&vd_source=27c6f8b829f0dd33f5100074447c107e
后续:vit-FRCNN(detection) SETR(segmentation) swin-Transformer
VIT-G
iGPT,MAE(生成式网络)
内容
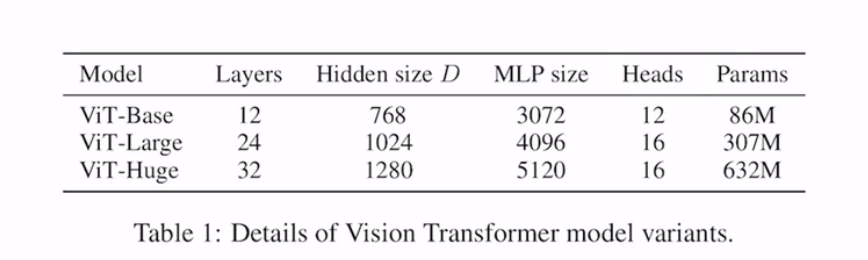
学习BERT,增加一个cls(extra learnable class embedding),在attention后可以获取到其他token的信息。
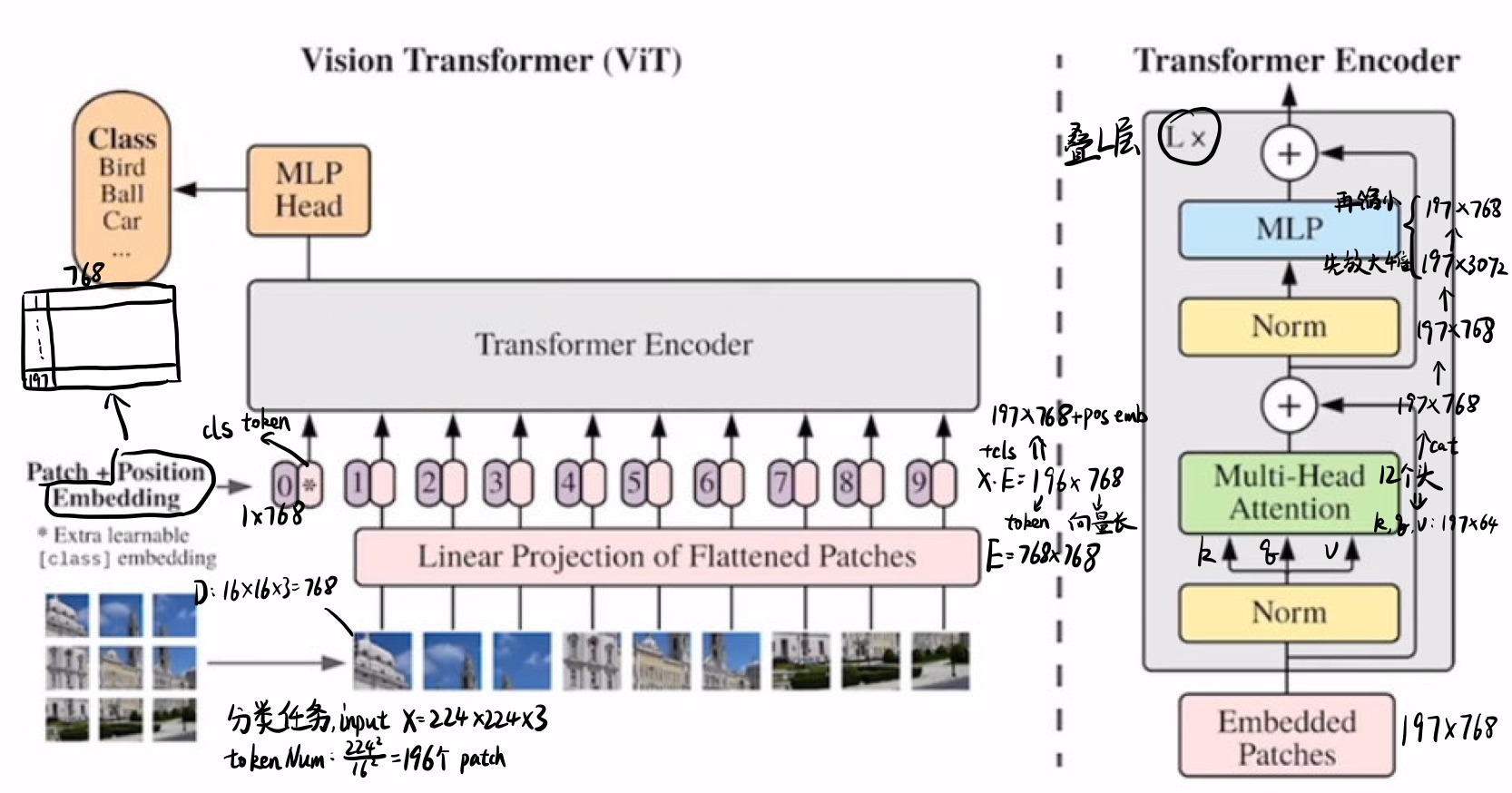
如果直接用GAP(Global Average Pooling(在过encoder之后,用GAP处理一下token,即可得到输出特征),也是work的,但是lr要低一些
postion embedding
1D
向量 1 2 3 4 5 --- 9 (
2D
矩阵,(
relative positional embedding
不使用绝对距离,使用相对距离(offset)
conclude
performence差不多,可能是网络感知patch之间位置很简单,so哪种方案都可以
一些分析
vit是比较纯粹的transformer,大部分不包含vision的特征与trick。
比如inductive bias(归纳偏置):locality局部性,还有!translation equivariance
而ViT只有MLP存在这个,在中小dataset差一些,但在大dataset就work了